问题面
- 上下文失真:不可见知识无法被运行时推理,Agent 只能在当前可读仓库内决策。
- 质量假阳性:CI 通过不等于平台真实可运行。
- 流程不可追溯:缺少 step/session 级别状态与失败原因,复盘成本高。
- 熵增积累:局部修补越来越多,长期技术债加速复利。
ForgeOps 不是“再包一层 Agent CLI”。 它是 AI 研发流水线的控制系统, 把 Issue -> Run -> Step -> PR 的全链路变成可观测、可恢复、可治理的工程机制。
在 Agent 驱动研发里,问题不只是“能不能更快写代码”,而是如何避免反复踩坑、架构漂移和文档失真。 ForgeOps 把失败视为可编程信号:不只修一次结果,而是补一条机制,降低同类错误复发率。
短 `AGENTS.md` 做地图,深层知识放仓库文档,技能通过 `agent-skills.json -> SKILL.md` 按需装配(按 step 精准装配,并可基于 issue 意图自动追加)。
把边界、不变量、依赖方向写成可执行规则,错误信息直接成为下一轮修复指令。
run / step / session 全链路可追踪,失败带结构化原因,状态区分 CI Gate 与 Platform Gate。
周期任务扫描文档漂移与架构退化,自动提出修复,持续回写质量文档与规则基线。
明确结构与约束,给后续步骤提供稳定边界。
将需求升级为结构化 issue,缺失信息补齐假设与偏好信号。
在独立 worktree 与分支中开发,完成后自动提交并创建/复用 PR。
执行测试、平台验收与不变量检查,必要时触发有限次自愈。
收敛熵增并产出技能候选,支持后续晋升为项目或 user-global 能力。
运行时抽象稳定,当前默认接入 `codex exec --json`,边界设计支持后续多运行时扩展。
`run create` 前强校验仓库与凭据,Issue-Only 绑定需求来源,分支命名与 worktree 隔离固定化。
进程重启后可回收孤儿步骤,优先复用 thread 续跑,失败再回退同 step 重跑,不丢落盘成果。
机械执行不变量检查,并将平台 preflight/smoke 纳入 `test` 闸门,避免“只过 CI”的假完成。
项目级 Cron 统一托管 cleanup、issue auto-run、skill promotion、global skill promotion。
技能候选可走独立 Draft PR 人审链路,与需求交付 DAG 解耦,避免主流程被治理动作拖慢。
Issue 是 run 的唯一需求入口,可按 `quick` / `standard` 标签路由执行模式。
系统为 run 创建独立目录 `
Worker 认领可执行节点并运行,状态与事件通过 API + SSE 实时输出到仪表盘。
在关键步骤后执行不变量和平台验收,配置允许时可触发预算内自动修复回合。
按 `workflow.yaml` 策略自动合并、回写 issue 状态,并尝试清理 run worktree 与本地分支。
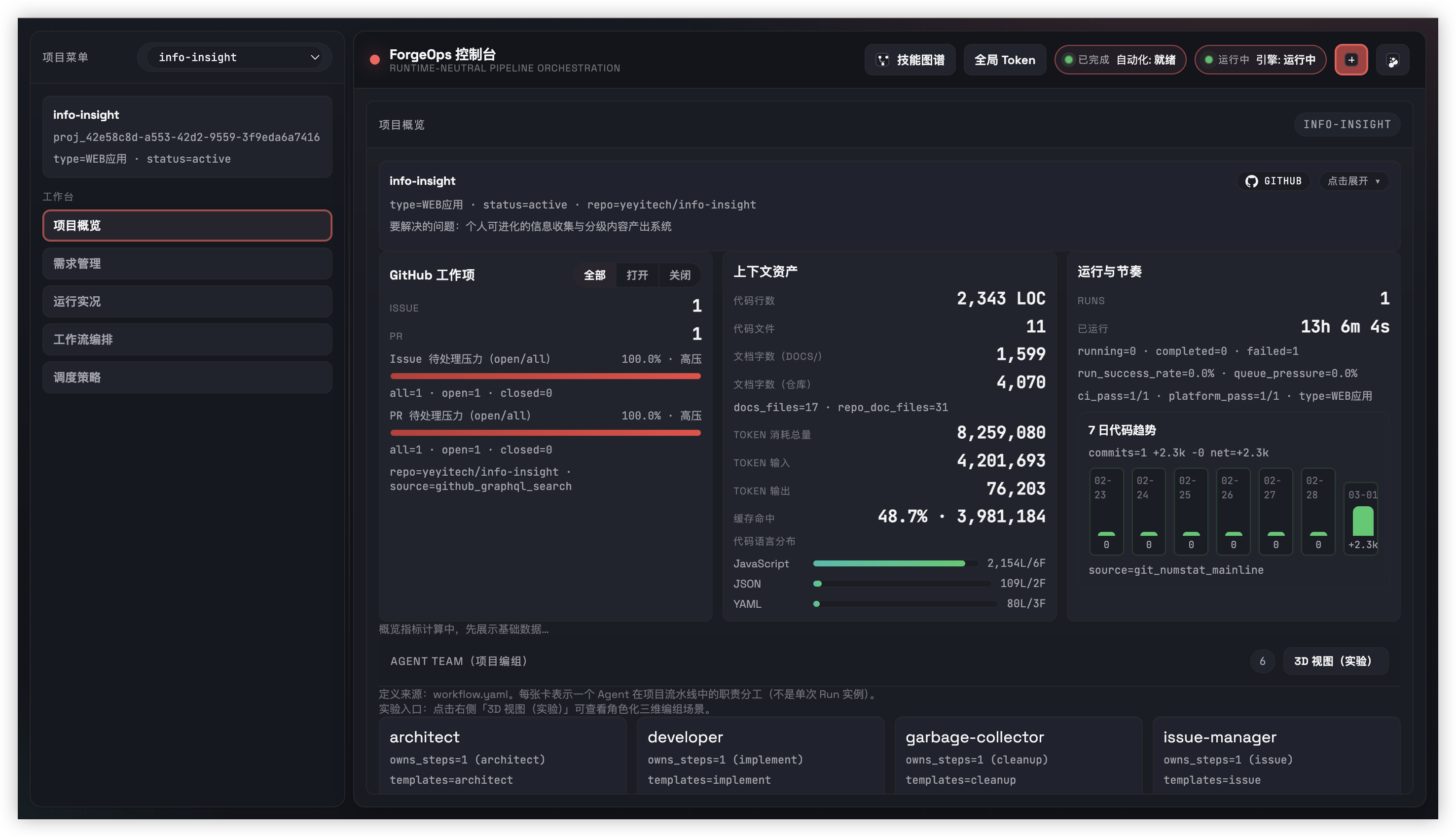
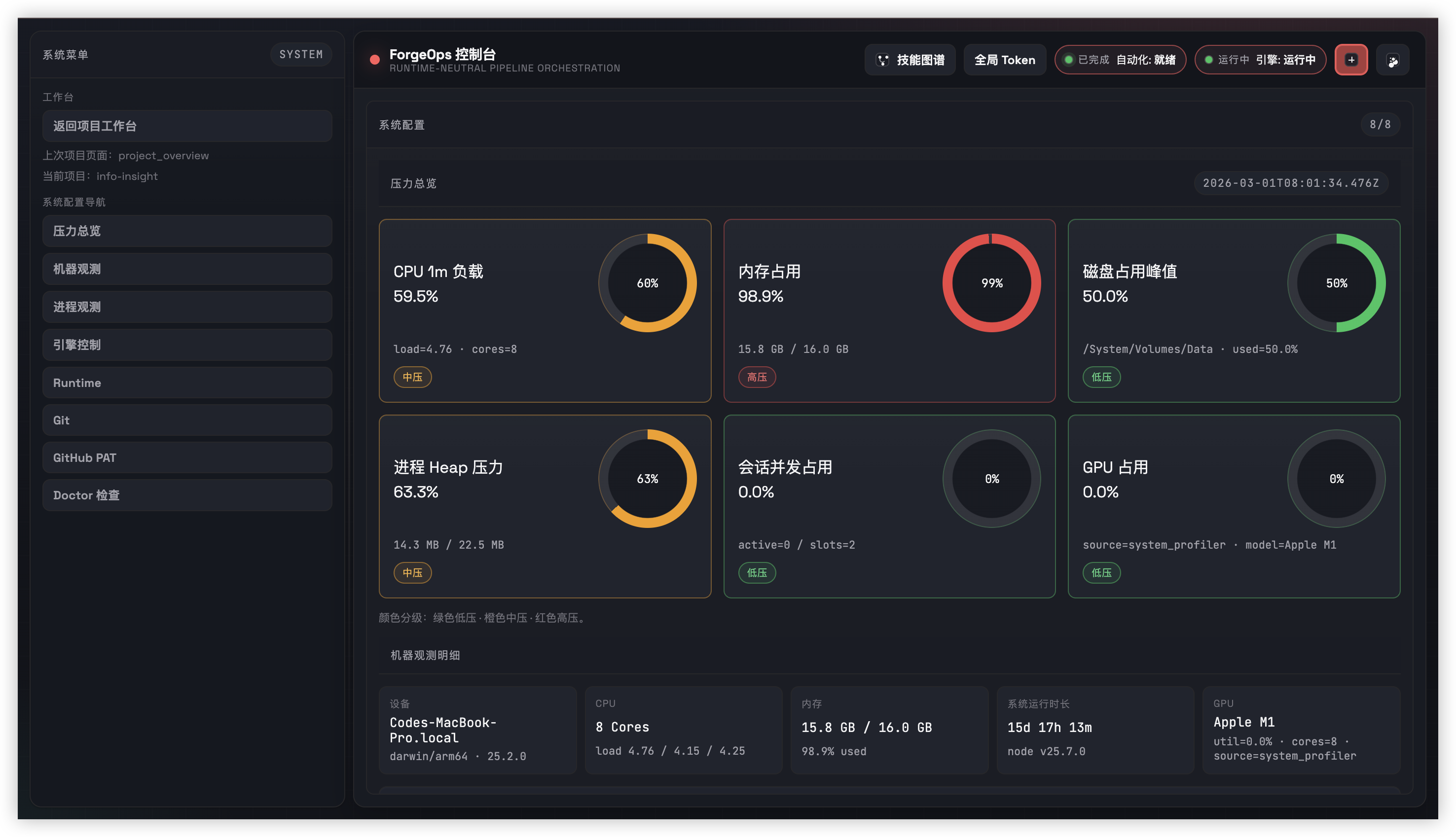
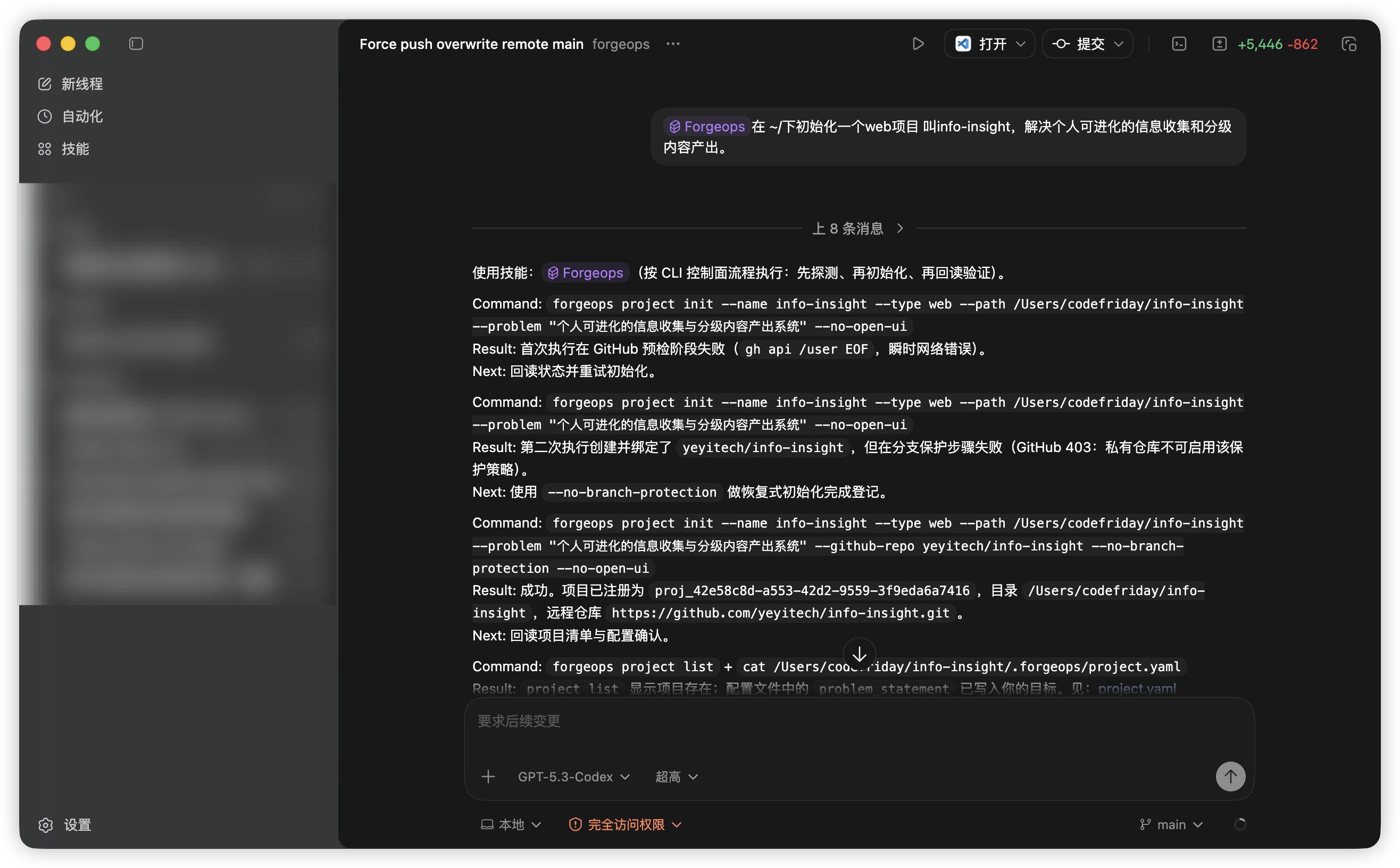
这个页面使用了 ForgeOps 仓库中可核实的事实(README、Architecture、Harness 指南、User Guide)。 如果你要继续扩展为官网版本,建议先补齐“真实运行指标、用户案例、部署链接”三类证据,再做下一轮视觉深化。